Obliczanie wartości średniej na podstawie określonych danych. Obliczanie wartości średniej w programie Microsoft Excel
Najpowszechniejszą formą wskaźników statystycznych stosowanych w badaniach społeczno-ekonomicznych jest wartość średnia, która jest uogólnioną cechą ilościową znaku populacji statystycznej. Wartości średnie są niejako „przedstawicielami” całej serii obserwacji. W wielu przypadkach średnią można wyznaczyć poprzez początkowy stosunek średniej (ISS) lub jej logiczny wzór: . Na przykład, aby obliczyć średnie wynagrodzenie pracowników przedsiębiorstwa, należy podzielić całkowity fundusz wynagrodzeń przez liczbę pracowników: Licznik początkowego stosunku średniej jest jej wskaźnikiem definiującym. W przypadku przeciętnego wynagrodzenia takim wskaźnikiem determinującym jest fundusz wynagrodzeń. Dla każdego wskaźnika użytego w analizie społeczno-ekonomicznej można zestawić tylko jeden prawdziwy wskaźnik referencyjny w celu obliczenia średniej. Należy też dodać, że w celu dokładniejszego oszacowania odchylenia standardowego dla małych próbek (o liczbie elementów mniejszej niż 30) w mianowniku wyrażenia pod pierwiastkiem nie należy stosować N, A N- 1.
Pojęcie i rodzaje średnich
Średnia wartość- jest to uogólniający wskaźnik populacji statystycznej, który niweluje indywidualne różnice w wartościach wielkości statystycznych, umożliwiając porównywanie ze sobą różnych populacji. Istnieje 2 zajęcia wartości średnie: mocy i strukturalne. Średnie strukturalne są moda I mediana , ale najczęściej używany średnie moce różne rodzaje.Średnie mocy
Średnie moce mogą być prosty I ważony.
Prostą średnią oblicza się, gdy istnieją dwie lub więcej niezgrupowanych wartości statystycznych, ułożonych w dowolnej kolejności zgodnie z następującym ogólnym wzorem prawa mocy średniej (dla różnych wartości k (m)):
Średnią ważoną oblicza się ze statystyk pogrupowanych, stosując następujący wzór ogólny:
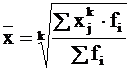
Gdzie x - średnia wartość badanego zjawiska; x i – i-ty wariant cechy uśrednionej;
f i jest wagą i-tej opcji.

Gdzie X to wartości poszczególnych wartości statystycznych lub punkty środkowe przedziałów grupujących;
m - wykładnik, od wartości którego zależą następujące rodzaje średnich mocy:
przy m = -1 średnia harmoniczna;
dla m = 0, średnia geometryczna;
dla m = 1, średnia arytmetyczna;
przy m = 2, średnia kwadratowa;
przy m = 3, średnia sześcienna.
Korzystając ze wzorów ogólnych na średnie proste i średnie ważone przy różnych wykładnikach m, otrzymujemy poszczególne wzory każdego typu, które zostaną szczegółowo omówione poniżej.
Średnia arytmetyczna
Średnia arytmetyczna - moment początkowy pierwszego rzędu, matematyczne oczekiwanie wartości zmiennej losowej przy dużej liczbie prób;
Średnia arytmetyczna jest najczęściej stosowaną wartością średnią, którą uzyskuje się przez podstawienie m = 1 do wzoru ogólnego. Średnia arytmetyczna prosty ma następującą postać:
 Lub
Lub ![]()
Gdzie X to wartości wielkości, dla których należy obliczyć wartość średnią; N to całkowita liczba wartości X (liczba jednostek w badanej populacji).
Przykładowo uczeń zdał 4 egzaminy i otrzymał oceny: 3, 4, 4 i 5. Średni wynik obliczmy korzystając z prostego wzoru na średnią arytmetyczną: (3+4+4+5)/4 = 16/4 = 4.Średnia arytmetyczna ważony ma następującą postać:

Gdzie f to liczba wartości o tej samej wartości X (częstotliwość). >Przykładowo uczeń zdał 4 egzaminy i otrzymał oceny: 3, 4, 4 i 5. Oblicz średni wynik, korzystając ze wzoru na średnią arytmetyczną ważoną: (3*1 + 4*2 + 5*1)/4 = 16/4 = 4 . Jeżeli wartości X podane są w formie przedziałów, wówczas do obliczeń wykorzystywane są punkty środkowe przedziałów X, które definiuje się jako połowę sumy górnej i dolnej granicy przedziału. A jeśli przedział X nie ma dolnej ani górnej granicy (przedział otwarty), to aby go znaleźć, stosuje się zakres (różnicę między górną i dolną granicą) sąsiedniego przedziału X. Na przykład w przedsiębiorstwie zatrudnionych jest 10 pracowników ze stażem pracy do 3 lat, 20 - ze stażem pracy od 3 do 5 lat, 5 pracowników - ze stażem pracy powyżej 5 lat. Następnie obliczamy średni staż pracy pracowników korzystając ze wzoru na średnią arytmetyczną ważoną, przyjmując jako X środek długości stażu pracy (2, 4 i 6 lat): (2*10+4*20+6*5)/(10+20+5) = 3,71 lat.
Funkcja ŚREDNIA
Ta funkcja oblicza średnią (arytmetyczną) swoich argumentów.
ŚREDNIA(liczba1, liczba2, ...)
Liczba1, liczba2, ... to od 1 do 30 argumentów, dla których obliczana jest średnia.
Argumenty muszą być liczbami lub nazwami, tablicami lub odniesieniami zawierającymi liczby. Jeżeli argument będący tablicą lub łączem zawiera teksty, wartości logiczne lub puste komórki, wówczas wartości te są ignorowane; jednak zliczane są komórki zawierające wartości null.
Funkcja ŚREDNIA
Oblicza średnią arytmetyczną wartości podanych na liście argumentów. Oprócz liczb w obliczeniach mogą brać udział teksty i wartości logiczne, takie jak PRAWDA i FAŁSZ.
ŚREDNIA(wartość1, wartość2,...)
Wartość1, wartość2,... to od 1 do 30 komórek, zakresów komórek lub wartości, dla których obliczana jest średnia.
Argumenty muszą być liczbami, nazwami, tablicami lub odwołaniami. Tablice i linki zawierające tekst są interpretowane jako 0 (zero). Pusty tekst („”) jest interpretowany jako 0 (zero). Argumenty zawierające wartość PRAWDA są interpretowane jako 1, Argumenty zawierające wartość FAŁSZ są interpretowane jako 0 (zero).
Najczęściej używana jest średnia arytmetyczna, ale zdarzają się przypadki, gdy potrzebne są inne typy średnich. Rozważmy takie przypadki dalej.
Średnia harmoniczna
Średnia harmoniczna do wyznaczania średniej sumy odwrotności;
Średnia harmoniczna stosuje się, gdy dane oryginalne nie zawierają częstotliwości f dla poszczególnych wartości X, lecz są prezentowane jako ich iloczyn Xf. Oznaczając Xf=w wyrażamy f=w/X i podstawiając te oznaczenia do wzoru na średnią arytmetyczną ważoną otrzymujemy wzór na średnią ważoną harmoniczną: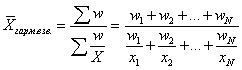
Zatem średnią ważoną harmoniczną stosuje się, gdy częstotliwości f są nieznane, ale znane jest w=Xf. W przypadkach, gdy wszystkie w=1, czyli poszczególne wartości X występują 1 raz, stosuje się prosty wzór na średnią harmoniczną: 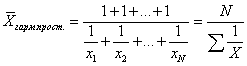 Lub
Lub  Przykładowo, samochód jechał z punktu A do punktu B z prędkością 90 km/h i z powrotem z prędkością 110 km/h. Aby określić średnią prędkość, stosujemy prosty wzór harmoniczny, ponieważ przykład podaje odległość w 1 \u003d w 2 (odległość od punktu A do punktu B jest taka sama jak od B do A), która jest równa iloczynowi prędkości (X) i czasu (f). Średnia prędkość = (1+1)/(1/90+1/110) = 99 km/h.
Przykładowo, samochód jechał z punktu A do punktu B z prędkością 90 km/h i z powrotem z prędkością 110 km/h. Aby określić średnią prędkość, stosujemy prosty wzór harmoniczny, ponieważ przykład podaje odległość w 1 \u003d w 2 (odległość od punktu A do punktu B jest taka sama jak od B do A), która jest równa iloczynowi prędkości (X) i czasu (f). Średnia prędkość = (1+1)/(1/90+1/110) = 99 km/h.
Funkcja SRHARM
Zwraca średnią harmoniczną zbioru danych. Średnia harmoniczna jest odwrotnością średniej arytmetycznej odwrotności.
SGARM(liczba1, liczba2, ...)
Liczba1, liczba2, ... to od 1 do 30 argumentów, dla których obliczana jest średnia. Zamiast argumentów rozdzielanych średnikami można użyć tablicy lub odwołania do tablicy.
Średnia harmoniczna jest zawsze mniejsza niż średnia geometryczna, która jest zawsze mniejsza niż średnia arytmetyczna.
Średnia geometryczna
Średnia geometryczna do szacowania średniego tempa wzrostu zmiennych losowych, znajdowania wartości cechy w jednakowej odległości od wartości minimalnej i maksymalnej;
Średnia geometryczna wykorzystywane do określania średnich zmian względnych. Wartość średniej geometrycznej daje najdokładniejszy wynik uśredniania, jeśli zadaniem jest znalezienie takiej wartości X, która byłaby w równej odległości zarówno od wartości maksymalnej, jak i minimalnej X. Na przykład w latach 2005-2008wskaźnik inflacji w Rosji było: w 2005 r. – 1,109; w 2006 r. – 1090; w 2007 r. – 1119; w 2008 r. – 1133. Ponieważ wskaźnik inflacji jest zmianą względną (wskaźnik dynamiczny), należy obliczyć średnią wartość za pomocą średniej geometrycznej: (1,109 * 1,090 * 1,119 * 1,133) ^ (1/4) = 1,1126, czyli dla okresu od 2005 do 2008 roku ceny rosły średnio o 11,26%. Błędne obliczenie średniej arytmetycznej dałoby błędny wynik wynoszący 11,28%.Funkcja SRGEOM
Zwraca średnią geometryczną tablicy lub zakresu liczb dodatnich. Na przykład funkcji CAGEOM można użyć do obliczenia średniej stopy wzrostu, jeśli podany jest dochód składany o zmiennych stopach.
SRGEOM(liczba1; liczba2; ...)
Liczba1, liczba2, ... to od 1 do 30 argumentów, dla których obliczana jest średnia geometryczna. Zamiast argumentów rozdzielanych średnikami można użyć tablicy lub odwołania do tablicy.
średnia kwadratowa
Średni kwadrat to moment początkowy drugiego rzędu.
średnia kwadratowa stosuje się, gdy początkowe wartości X mogą być zarówno dodatnie, jak i ujemne, na przykład przy obliczaniu średnich odchyleń.Przeciętny sześcienny
Średni sześcienny jest momentem początkowym trzeciego rzędu.
Przeciętny sześcienny jest stosowany niezwykle rzadko, np. przy obliczaniu wskaźników ubóstwa dla krajów rozwijających się (HPI-1) i krajów rozwiniętych (HPI-2), proponowanych i obliczanych przez ONZ.Jak obliczyć średnią liczb w programie Excel
Za pomocą tej funkcji możesz znaleźć średnią arytmetyczną liczb w programie Excel.
Składnia ŚREDNIA
=ŚREDNIA(liczba1,[liczba2],…) - Wersja rosyjska
Argumenty ŚREDNIE
- numer 1- pierwsza liczba lub zakres liczb, do obliczenia średniej arytmetycznej;
- numer 2(Opcjonalnie) – druga liczba lub zakres liczb do obliczenia średniej arytmetycznej. Maksymalna liczba argumentów funkcji wynosi 255.
Aby obliczyć, wykonaj następujące kroki:
- Wybierz dowolną komórkę;
- Napisz w nim formułę =ŚREDNIA(
- Wybierz zakres komórek, dla którego chcesz wykonać obliczenia;
- Naciśnij klawisz „Enter” na klawiaturze
Funkcja obliczy średnią wartość z określonego zakresu spośród komórek zawierających liczby.
Jak znaleźć średnią wartość danego tekstu
Jeśli w zakresie danych znajdują się puste linie lub tekst, funkcja traktuje je jako „zero”. Jeśli wśród danych znajdują się wyrażenia logiczne FAŁSZ lub PRAWDA, wówczas funkcja postrzega FAŁSZ jako „zero”, a PRAWDA jako „1”.
Jak znaleźć średnią arytmetyczną według warunku
Funkcja służy do obliczenia średniej według warunku lub kryterium. Załóżmy na przykład, że mamy dane dotyczące sprzedaży produktów:

Naszym zadaniem jest obliczenie średniej sprzedaży długopisów. Aby to zrobić, wykonamy następujące kroki:
- W celi A13 wpisz nazwę produktu „Długopisy”;
- W celi B13 wprowadźmy formułę:
=ŚREDNIAJEŻELI(A2:A10,A13,B2:B10)
Zakres komórek „ A2:A10” wskazuje na listę produktów, w których będziemy szukać słowa „Długopisy”. Argument A13 jest to link do komórki z tekstem, którego będziemy szukać wśród całej listy produktów. Zakres komórek „ B2:B10” to zakres zawierający dane sprzedażowe produktów, wśród których funkcja znajdzie „Pióra” i obliczy średnią wartość.

W procesie różnych obliczeń i pracy z danymi często konieczne jest obliczenie ich średniej wartości. Oblicza się go, dodając liczby i dzieląc sumę przez ich liczbę. Dowiedzmy się, jak obliczyć średnią zbioru liczb za pomocą programu Microsoft Excel na różne sposoby.
Najłatwiejszym i najbardziej znanym sposobem znalezienia średniej arytmetycznej zbioru liczb jest użycie specjalnego przycisku na wstążce programu Microsoft Excel. Wybieramy zakres liczb znajdujący się w kolumnie lub wierszu dokumentu. Będąc w zakładce „Strona główna” kliknij przycisk „Autosumowanie”, który znajduje się na wstążce w bloku narzędziowym „Edycja”. Z listy rozwijanej wybierz opcję „Średnia”.

Następnie za pomocą funkcji „ŚREDNIA” dokonuje się obliczeń. W komórce pod wybraną kolumną lub na prawo od wybranego wiersza wyświetlana jest średnia arytmetyczna danego zbioru liczb.

Ta metoda jest dobra ze względu na prostotę i wygodę. Ale ma też istotne wady. Za pomocą tej metody można obliczyć średnią wartość tylko tych liczb, które są ułożone w rzędzie w jednej kolumnie lub w jednym rzędzie. Jednak w przypadku tablicy komórek lub komórek rozproszonych na arkuszu nie można pracować przy użyciu tej metody.
Przykładowo, jeśli wybierzesz dwie kolumny i obliczysz średnią arytmetyczną w powyższy sposób, to odpowiedź zostanie podana dla każdej kolumny z osobna, a nie dla całej tablicy komórek.

Obliczenia za pomocą kreatora funkcji
W przypadkach, gdy trzeba obliczyć średnią arytmetyczną tablicy komórek lub komórek rozproszonych, można skorzystać z Kreatora funkcji. Nadal wykorzystuje tę samą funkcję ŚREDNIA, którą znamy z pierwszego sposobu obliczeń, ale robi to w nieco inny sposób.
Klikamy na komórkę, w której chcemy wyświetlić wynik obliczenia wartości średniej. Kliknij przycisk „Wstaw funkcję”, który znajduje się po lewej stronie paska formuły. Lub wpisujemy kombinację Shift + F3 na klawiaturze.

Zostanie uruchomiony Kreator funkcji. Na prezentowanej liście funkcji szukamy „ŚREDNIE”. Wybierz go i kliknij przycisk „OK”.

Otworzy się okno argumentów tej funkcji. Argumenty funkcji wpisuje się w pola „Numer”. Mogą to być zarówno zwykłe liczby, jak i adresy komórek, w których znajdują się te numery. Jeżeli ręczne wprowadzanie adresów komórek jest niewygodne, należy kliknąć przycisk znajdujący się po prawej stronie pola wprowadzania danych.

Następnie okno argumentów funkcji zwinie się i będziesz mógł wybrać grupę komórek na arkuszu, którą weźmiesz do obliczeń. Następnie ponownie kliknij przycisk po lewej stronie pola wprowadzania danych, aby powrócić do okna argumentów funkcji.

Jeśli chcesz obliczyć średnią arytmetyczną między liczbami w różnych grupach komórek, wykonaj te same kroki, które opisano powyżej w polu „Numer 2”. I tak dalej, aż zostaną wybrane wszystkie żądane grupy komórek.

Następnie kliknij przycisk „OK”.

Wynik obliczenia średniej arytmetycznej zostanie podświetlony w komórce wybranej przed uruchomieniem Kreatora funkcji.

Pasek formuły
Istnieje trzeci sposób uruchomienia funkcji „ŚREDNIA”. Aby to zrobić, przejdź do zakładki Formuły. Wybierz komórkę, w której zostanie wyświetlony wynik. Następnie w grupie narzędzi „Biblioteka funkcji” na wstążce kliknij przycisk „Inne funkcje”. Pojawi się lista, na której należy kolejno przeglądać pozycje „Statystyczne” i „ŚREDNIA”.

Następnie uruchamiane jest dokładnie to samo okno z argumentami funkcji, jak w przypadku korzystania z Kreatora funkcji, o którym szczegółowo pisaliśmy powyżej.

Dalsze kroki są dokładnie takie same.
Ręczne wprowadzanie funkcji
Ale nie zapominaj, że zawsze możesz ręcznie wprowadzić funkcję „ŚREDNIA”, jeśli chcesz. Będzie miał następujący wzór: „=ŚREDNIA(adres_zakresu_komórki(liczba); adres_zakresu_komórki(liczba)).

Oczywiście ta metoda nie jest tak wygodna jak poprzednie i wymaga trzymania w głowie użytkownika pewnych formuł, ale jest bardziej elastyczna.
Obliczanie wartości średniej według warunku
Oprócz zwykłego obliczania wartości średniej możliwe jest obliczenie wartości średniej według warunku. W takim przypadku pod uwagę brane będą tylko te liczby z wybranego zakresu, które spełniają określony warunek. Na przykład, jeśli te liczby są większe lub mniejsze od określonej wartości.
Do tych celów używana jest funkcja ŚREDNIA.JEŻELI. Podobnie jak funkcję ŚREDNIA, można ją uruchomić za pomocą Kreatora funkcji, z paska formuły lub ręcznie wprowadzając ją do komórki. Po otwarciu okna argumentów funkcji należy wprowadzić jej parametry. W polu „Zakres” wprowadź zakres komórek, których wartości zostaną wykorzystane do wyznaczenia średniej arytmetycznej. Robimy to analogicznie jak w przypadku funkcji ŚREDNIA.
I tutaj w polu „Warunek” musimy podać konkretną wartość, liczby większe lub mniejsze od tych, które będą brane pod uwagę w obliczeniach. Można to zrobić za pomocą znaków porównania. Na przykład przyjęliśmy wyrażenie „>=15000”. Oznacza to, że do obliczeń zostaną wzięte tylko komórki z zakresu zawierającego liczby większe lub równe 15000. W razie potrzeby zamiast konkretnej liczby możesz podać adres komórki, w której znajduje się odpowiednia liczba.
Pole „Zakres uśredniania” jest opcjonalne. Wprowadzanie do niego danych jest wymagane tylko w przypadku korzystania z komórek zawierających treść tekstową.
Po wprowadzeniu wszystkich danych kliknij przycisk „OK”.

Następnie we wstępnie wybranej komórce wyświetlany jest wynik obliczenia średniej arytmetycznej dla wybranego zakresu, za wyjątkiem komórek, których dane nie spełniają warunków.

Jak widać, w programie Microsoft Excel dostępnych jest szereg narzędzi, za pomocą których można obliczyć średnią wartość wybranego ciągu liczbowego. Ponadto dostępna jest funkcja automatycznego wybierania liczb z zakresu niespełniającego zdefiniowanych przez użytkownika kryteriów. Dzięki temu obliczenia w programie Microsoft Excel są jeszcze bardziej przyjazne dla użytkownika.
Najpopularniejszym typem średniej jest średnia arytmetyczna.
prosta średnia arytmetyczna
Prosta średnia arytmetyczna to średni termin określający, jaki całkowity wolumen danego atrybutu w danych rozkłada się równomiernie pomiędzy wszystkie jednostki zawarte w tej populacji. Zatem średnioroczna wielkość produkcji na pracownika to taka wartość wielkości produkcji, która przypadłaby na każdego pracownika, gdyby cała wielkość produkcji była równomiernie rozdzielona pomiędzy wszystkich pracowników organizacji. Średnią arytmetyczną prostą wartość oblicza się ze wzoru:
Przykład 1 . Zespół 6 pracowników otrzymuje 3 3,2 3,3 3,5 3,8 3,1 tysiąca rubli miesięcznie.prosta średnia arytmetyczna— Równy stosunkowi sumy poszczególnych wartości cechy do liczby cech w sumie
Znajdź średnią pensję
Rozwiązanie: (3 + 3,2 + 3,3 +3,5 + 3,8 + 3,1) / 6 = 3,32 tys. Rubli.
Średnia arytmetyczna ważona
Jeżeli objętość zbioru danych jest duża i stanowi szereg dystrybucyjny, wówczas obliczana jest ważona średnia arytmetyczna. W ten sposób wyznacza się średnią ważoną cenę jednostki produkcji: całkowity koszt produkcji (suma produktów jej ilości i ceny jednostki produkcji) jest dzielony przez całkowitą wielkość produkcji.
Przedstawiamy to w postaci następującego wzoru:
![]()
Przykład 2 . Znajdź średnie miesięczne zarobki pracowników sklepówWażona średnia arytmetyczna- jest równy stosunkowi (suma iloczynów wartości atrybutu przez częstotliwość powtarzania się tego atrybutu) do (suma częstości występowania wszystkich atrybutów). Stosuje się go, gdy warianty badanej populacji występują nierówno kilka razy.
Przeciętne wynagrodzenie można otrzymać, dzieląc wynagrodzenie całkowite przez całkowitą liczbę pracowników:

Odpowiedź: 3,35 tysiąca rubli.
Średnia arytmetyczna szeregu przedziałowego
Obliczając średnią arytmetyczną szeregu zmian przedziałowych, najpierw wyznacza się średnią dla każdego przedziału jako połowę sumy górnej i dolnej granicy, a następnie średnią z całego szeregu. W przypadku przedziałów otwartych o wartości przedziału dolnego lub górnego decyduje wartość przedziałów sąsiadujących z nimi.
Średnie obliczone z szeregów przedziałowych są przybliżone.
Przykład 3. Określ średni wiek studentów na wydziale wieczorowym.

Średnie obliczone z szeregów przedziałowych są przybliżone. Stopień ich przybliżenia zależy od tego, na ile rzeczywisty rozkład jednostek populacji w obrębie przedziału zbliża się do równomierności.
Przy obliczaniu średnich jako wagi można stosować nie tylko wartości bezwzględne, ale także względne (częstotliwość):
Średnia arytmetyczna ma wiele właściwości, które pełniej ujawniają jej istotę i upraszczają obliczenia:
1. Iloczyn średniej i sumy częstotliwości jest zawsze równy sumie iloczynów wariantu i częstotliwości, tj.
![]()
2. Średnia arytmetyczna sumy zmiennych wielkości jest równa sumie średnich arytmetycznych tych wielkości:
3. Suma algebraiczna odchyleń poszczególnych wartości atrybutu od średniej wynosi zero:
![]()
4. Suma kwadratów odchyleń opcji od średniej jest mniejsza niż suma kwadratów odchyleń od dowolnej innej dowolnej wartości, tj.
W większości przypadków dane są skupione wokół jakiegoś centralnego punktu. Zatem, aby opisać dowolny zbiór danych, wystarczy wskazać wartość średnią. Rozważmy kolejno trzy cechy liczbowe, które służą do oszacowania wartości średniej rozkładu: średnią arytmetyczną, medianę i modę.
Przeciętny
Średnia arytmetyczna (często nazywana po prostu średnią) jest najczęstszym oszacowaniem średniej rozkładu. Jest to wynik podzielenia sumy wszystkich zaobserwowanych wartości liczbowych przez ich liczbę. Dla próbki liczb X 1, X 2, ..., XN, średnia próbki (oznaczona symbolem ) równa się \u003d (X 1 + X 2 + ... + XN) / N, Lub
gdzie jest średnia z próbki, N- wielkość próbki, XI– i-ty element próbki.
Pobierz notatkę w formacie lub, przykłady w formacie
Rozważ obliczenie średniej arytmetycznej pięcioletnich średnich rocznych stóp zwrotu 15 funduszy inwestycyjnych bardzo wysokiego ryzyka (rysunek 1).

Ryż. 1. Średni roczny zwrot z 15 funduszy inwestycyjnych bardzo wysokiego ryzyka
Średnią próbkę oblicza się w następujący sposób:

Jest to dobry wynik, szczególnie w porównaniu z stopą zwrotu, jaką w tym samym okresie otrzymywali deponenci banków lub spółdzielczych kas oszczędnościowo-kredytowych na poziomie 3–4%. Jeśli posortować wartości zwrotu, łatwo zauważyć, że osiem funduszy ma stopę zwrotu powyżej, a siedem poniżej średniej. Średnia arytmetyczna pełni rolę punktu równowagi, tak że fundusze o niskich dochodach równoważą fundusze o wysokich dochodach. W obliczeniu średniej biorą udział wszystkie elementy próby. Żaden z pozostałych estymatorów rozkładu średniego nie ma tej własności.
Kiedy obliczać średnią arytmetyczną. Ponieważ średnia arytmetyczna zależy od wszystkich elementów próbki, obecność wartości ekstremalnych znacząco wpływa na wynik. W takich sytuacjach średnia arytmetyczna może zniekształcić znaczenie danych liczbowych. Dlatego przy opisie zbioru danych zawierającego wartości ekstremalne konieczne jest wskazanie mediany lub średniej arytmetycznej i mediany. Na przykład, jeśli z próby usuniemy zwrot funduszu RS Emerging Growth, średnia z próby 14 funduszy zmniejszy się o prawie 1% do 5,19%.
Mediana
Mediana to środkowa wartość uporządkowanej tablicy liczb. Jeśli tablica nie zawiera powtarzających się liczb, to połowa jej elementów będzie mniejsza, a połowa większa od mediany. Jeśli próbka zawiera wartości ekstremalne, do oszacowania średniej lepiej jest zastosować medianę, a nie średnią arytmetyczną. Aby obliczyć medianę próbki, należy ją najpierw posortować.
Formuła ta jest niejednoznaczna. Jego wynik zależy od tego, czy liczba jest parzysta, czy nieparzysta. N:
- Jeśli próbka zawiera nieparzystą liczbę elementów, mediana wynosi (n+1)/2-ty element.
- Jeżeli próbka zawiera parzystą liczbę elementów, mediana leży pomiędzy dwoma środkowymi elementami próbki i jest równa średniej arytmetycznej obliczonej z tych dwóch elementów.
Aby obliczyć medianę dla próby 15 funduszy inwestycyjnych bardzo wysokiego ryzyka, musimy najpierw posortować surowe dane (rysunek 2). Wtedy mediana będzie przeciwna numerowi środkowego elementu próbki; w naszym przykładzie nr 8. Excel ma specjalną funkcję =MEDIAN(), która działa również z tablicami nieuporządkowanymi.

Ryż. 2. Mediana 15 funduszy
Zatem mediana wynosi 6,5. Oznacza to, że połowa funduszy bardzo wysokiego ryzyka nie przekracza 6,5, a druga połowa tak. Należy zauważyć, że mediana 6,5 jest nieco większa niż mediana 6,08.
Jeżeli z próby usuniemy rentowność funduszu RS Emerging Growth, to mediana pozostałych 14 funduszy obniży się do 6,2%, czyli nie tak znacząco, jak średnia arytmetyczna (rys. 3).

Ryż. 3. Mediana 14 funduszy
Moda
Termin ten został po raz pierwszy wprowadzony przez Pearsona w 1894 roku. Moda to liczba, która występuje najczęściej w próbie (najmodniejsza). Moda dobrze opisuje na przykład typową reakcję kierowców na sygnalizację świetlną nakazującą zatrzymanie ruchu. Klasycznym przykładem zastosowania mody jest wybór rozmiaru produkowanej partii butów czy koloru tapety. Jeśli rozkład ma wiele postaci, wówczas mówi się, że jest multimodalny lub multimodalny (ma dwa lub więcej „szczytów”). Rozkład multimodalny dostarcza ważnych informacji o naturze badanej zmiennej. Na przykład w badaniach socjologicznych, jeśli zmienna reprezentuje preferencje lub postawę wobec czegoś, wówczas multimodalność może oznaczać, że istnieje kilka wyraźnie różnych opinii. Multimodalność jest również wskaźnikiem, że próbka nie jest jednorodna i że obserwacje mogą być generowane przez dwa lub więcej „nakładających się” rozkładów. W przeciwieństwie do średniej arytmetycznej wartości odstające nie wpływają na tryb. W przypadku zmiennych losowych o rozkładzie ciągłym, takich jak średnia roczna stopa zwrotu z funduszy inwestycyjnych, tryb ten czasami w ogóle nie istnieje (lub nie ma sensu). Ponieważ wskaźniki te mogą przyjmować różne wartości, powtarzające się wartości są niezwykle rzadkie.
Kwartyle
Kwartyle to miary najczęściej używane do oceny rozkładu danych przy opisywaniu właściwości dużych próbek numerycznych. Podczas gdy mediana dzieli uporządkowaną tablicę na pół (50% elementów tablicy jest mniejszych od mediany, a 50% jest większych), kwartyle dzielą uporządkowany zbiór danych na cztery części. Wartości Q 1 , mediana i Q 3 to odpowiednio 25., 50. i 75. percentyl. Pierwszy kwartyl Q 1 to liczba dzieląca próbę na dwie części: 25% elementów jest mniejszych i 75% większych niż pierwszy kwartyl.
Trzeci kwartyl Q 3 to liczba, która również dzieli próbę na dwie części: 75% elementów jest mniejszych, a 25% większych niż trzeci kwartyl.
Do obliczenia kwartylów w wersjach Excela wcześniejszych niż 2007 użyto funkcji =KWARTYL(tablica, część). Począwszy od Excela 2010, obowiązują dwie funkcje:
- =KWARTYL.ON(tablica, część)
- =KWARTYL.WYK(tablica, część)
Te dwie funkcje dają nieco inne wartości (rysunek 4). Na przykład przy obliczaniu kwartylów dla próby zawierającej dane dotyczące średniej rocznej stopy zwrotu 15 funduszy wspólnego inwestowania bardzo wysokiego ryzyka Q 1 = 1,8 lub -0,7 odpowiednio dla QUARTILE.INC i QUARTILE.EXC. Nawiasem mówiąc, używana wcześniej funkcja QUARTILE odpowiada nowoczesnej funkcji QUARTILE.ON. Aby obliczyć kwartyle w programie Excel przy użyciu powyższych wzorów, tablicę danych można pozostawić nieuporządkowaną.

Ryż. 4. Oblicz kwartyle w Excelu
Podkreślmy jeszcze raz. Excel może obliczyć kwartyle dla jednej zmiennej dyskretna seria, zawierający wartości zmiennej losowej. Obliczanie kwartylów dla rozkładu opartego na częstotliwości podano w poniższej sekcji.
Średnia geometryczna
W przeciwieństwie do średniej arytmetycznej, średnia geometryczna mierzy, jak bardzo zmienna zmieniła się w czasie. Średnia geometryczna to pierwiastek N stopień od produktu N wartości (w Excelu używana jest funkcja = CUGEOM):
G= (X 1 * X 2 * ... * X n) 1/n
Podobny parametr – średnią geometryczną stopy zwrotu – wyznacza wzór:
G \u003d [(1 + R 1) * (1 + R 2) * ... * (1 + R n)] 1 / n - 1,
Gdzie R ja- stopa zwrotu I-ty okres czasu.
Załóżmy na przykład, że początkowa inwestycja wynosi 100 000 USD, pod koniec pierwszego roku spada do 50 000 USD, a pod koniec drugiego roku wraca do pierwotnych 100 000 USD. Stopa zwrotu z tej inwestycji w ciągu dwóch lat okres roku jest równy 0, ponieważ początkowa i końcowa kwota środków są sobie równe. Natomiast średnia arytmetyczna rocznych stóp zwrotu wynosi = (-0,5 + 1) / 2 = 0,25 czyli 25%, gdyż stopa zwrotu w pierwszym roku R 1 = (50 000 - 100 000) / 100 000 = -0,5 , a w drugim R 2 = (100 000 - 50 000) / 50 000 = 1. Jednocześnie średnia geometryczna stopy zwrotu za dwa lata wynosi: G = [(1–0,5) * (1 + 1 )] 1 /2 – 1 = ½ – 1 = 1 – 1 = 0. Zatem średnia geometryczna dokładniej odzwierciedla zmianę (a dokładniej brak zmiany) wolumenu inwestycji w ciągu dwóch lat niż średnia arytmetyczna.
Interesujące fakty. Po pierwsze, średnia geometryczna będzie zawsze mniejsza niż średnia arytmetyczna tych samych liczb. Z wyjątkiem przypadku, gdy wszystkie wzięte liczby są sobie równe. Po drugie, po rozważeniu właściwości trójkąta prostokątnego, można zrozumieć, dlaczego średnią nazywa się geometryczną. Wysokość trójkąta prostokątnego obniżonego do przeciwprostokątnej jest średnią proporcjonalną między rzutami nóg na przeciwprostokątną, a każda noga jest średnią proporcjonalną między przeciwprostokątną a jej rzutem na przeciwprostokątną (ryc. 5). Daje to geometryczny sposób konstruowania średniej geometrycznej dwóch (długości) odcinków: należy zbudować okrąg z sumy tych dwóch odcinków jako średnicy, a następnie wysokości, przywróconej od punktu ich połączenia do przecięcia z okrąg, da żądaną wartość:

Ryż. 5. Geometryczna natura średniej geometrycznej (rysunek z Wikipedii)
Drugą ważną właściwością danych liczbowych jest ich zmiana charakteryzujących stopień rozproszenia danych. Dwie różne próbki mogą różnić się zarówno wartościami średnimi, jak i odmianami. Jednakże, jak pokazano na rys. 6 i 7, dwie próbki mogą mieć tę samą zmienność, ale różne średnie, lub tę samą średnią i zupełnie inną zmienność. Dane odpowiadające wielokątowi B na ryc. 7 zmieniają się znacznie mniej niż dane, z których zbudowano wielokąt A.

Ryż. 6. Dwa symetryczne rozkłady dzwonowe z tym samym rozrzutem i różnymi wartościami średnimi

Ryż. 7. Dwa symetryczne rozkłady dzwonowe o tych samych wartościach średnich i różnym rozproszeniu
Istnieje pięć szacunków zmienności danych:
- Zakres,
- zakres międzykwartylowy,
- dyspersja,
- odchylenie standardowe,
- współczynnik zmienności.
zakres
Rozstęp to różnica pomiędzy największymi i najmniejszymi elementami próbki:
Przesuń = XMax-XMin
Rozpiętość próby zawierającej średnie roczne zyski 15 funduszy inwestycyjnych bardzo wysokiego ryzyka można obliczyć za pomocą uporządkowanej tablicy (zob. wykres 4): zakres = 18,5 – (-6,1) = 24,6. Oznacza to, że różnica pomiędzy najwyższą i najniższą średnioroczną stopą zwrotu dla funduszy bardzo wysokiego ryzyka wynosi 24,6%.
Zakres mierzy ogólny rozrzut danych. Chociaż zakres próby jest bardzo prostym oszacowaniem całkowitego rozrzutu danych, jego słabością jest to, że nie uwzględnia dokładnego rozkładu danych pomiędzy elementami minimalnymi i maksymalnymi. Efekt ten jest dobrze widoczny na ryc. 8, która ilustruje próbki mające ten sam zakres. Skala B pokazuje, że jeśli próbka zawiera co najmniej jedną wartość ekstremalną, zakres próbki jest bardzo niedokładnym oszacowaniem rozproszenia danych.

Ryż. 8. Porównanie trzech próbek o tym samym zakresie; trójkąt symbolizuje podparcie wagi, a jego położenie odpowiada średniej wartości próbki
Zakres międzykwartylowy
Rozstęp międzykwartylowy, czyli średni, to różnica między trzecim a pierwszym kwartylem próbki:
Rozstęp międzykwartylowy \u003d Q 3 - Q 1
Wartość ta pozwala oszacować rozrzut 50% pierwiastków i nie uwzględniać wpływu pierwiastków skrajnych. Rozstęp międzykwartylowy dla próby zawierającej dane dotyczące średniorocznych stóp zwrotu 15 funduszy inwestycyjnych bardzo wysokiego ryzyka można obliczyć, korzystając z danych przedstawionych na ryc. 4 (przykładowo dla funkcji KWARTYL.WYK): Rozstęp międzykwartylowy = 9,8 - (-0,7) = 10,5. Przedział między 9,8 a -0,7 jest często nazywany środkową połową.
Należy zaznaczyć, że wartości Q 1 i Q 3, a co za tym idzie rozstęp międzykwartylowy, nie zależą od obecności wartości odstających, gdyż w ich obliczeniach nie uwzględnia się żadnej wartości, która byłaby mniejsza niż Q 1 lub większa niż Q 3 . Całkowite cechy ilościowe, takie jak mediana, pierwszy i trzeci kwartyl oraz rozstęp międzykwartylowy, na które nie mają wpływu wartości odstające, nazywane są solidnymi wskaźnikami.
Chociaż rozstęp i rozstęp międzykwartylowy umożliwiają oszacowanie odpowiednio całkowitego i średniego rozrzutu próbki, żadne z tych szacunków nie uwzględnia dokładnego rozkładu danych. Wariancja i odchylenie standardowe wolny od tej wady. Wskaźniki te pozwalają ocenić stopień fluktuacji danych wokół średniej. Odchylenie próbki jest przybliżeniem średniej arytmetycznej obliczonej na podstawie kwadratów różnic między każdym elementem próbki a średnią z próbki. Dla próbki X 1 , X 2 , ... X n wariancję próbki (oznaczoną symbolem S 2 wyraża się następującym wzorem:

Ogólnie rzecz biorąc, wariancja próbki to suma kwadratów różnic między elementami próbki a średnią próbki, podzielona przez wartość równą wielkości próby minus jeden:

Gdzie - Średnia arytmetyczna, N- wielkość próbki, X ja - I-ty przykładowy element X. W programie Excel przed wersją 2007 do obliczenia wariancji próbki używana była funkcja =VAR() , od wersji 2010 używana jest funkcja =VAR.V().
Najbardziej praktycznym i powszechnie akceptowanym oszacowaniem rozproszenia danych jest odchylenie standardowe. Wskaźnik ten jest oznaczony symbolem S i jest równy pierwiastkowi kwadratowemu wariancji próbki:

W Excelu przed wersją 2007 do obliczenia odchylenia standardowego używana była funkcja =STDEV() , od wersji 2010 używana jest funkcja =STDEV.B(). Aby obliczyć te funkcje, tablica danych może być nieuporządkowana.
Ani wariancja próbki, ani odchylenie standardowe próbki nie mogą być ujemne. Jedyną sytuacją, w której wskaźniki S 2 i S mogą wynosić zero, jest sytuacja, gdy wszystkie elementy próby są równe. W tym całkowicie nieprawdopodobnym przypadku rozstęp i rozstęp międzykwartylowy również wynoszą zero.
Dane liczbowe są z natury niestabilne. Każda zmienna może przyjmować wiele różnych wartości. Na przykład różne fundusze wspólnego inwestowania mają różne stopy zwrotu i straty. Ze względu na zmienność danych liczbowych bardzo ważne jest badanie nie tylko oszacowań średniej, które mają charakter sumatywny, ale także oszacowań wariancji, które charakteryzują rozrzut danych.
Wariancja i odchylenie standardowe pozwalają oszacować rozproszenie danych wokół średniej, innymi słowy określić, ile elementów próby jest mniejszych od średniej, a ile większych. Dyspersja ma pewne cenne właściwości matematyczne. Jednak jego wartość to kwadrat jednostki miary - procent kwadratowy, dolar kwadratowy, cal kwadratowy itp. Dlatego naturalnym oszacowaniem wariancji jest odchylenie standardowe wyrażane w zwykłych jednostkach miary - procentach dochodu, dolarach lub calach.
Odchylenie standardowe pozwala oszacować wielkość fluktuacji elementów próbki wokół wartości średniej. Prawie we wszystkich sytuacjach większość obserwowanych wartości mieści się w granicach plus minus jedno odchylenie standardowe od średniej. Znając zatem średnią arytmetyczną elementów próby oraz odchylenie standardowe próby, można wyznaczyć przedział, do którego należy większość danych.
Odchylenie standardowe zwrotów z 15 funduszy inwestycyjnych bardzo wysokiego ryzyka wynosi 6,6 (wykres 9). Oznacza to, że rentowność większości funduszy odbiega od średniej o nie więcej niż 6,6% (tj. waha się w przedziale od - S= 6,2 – 6,6 = –0,4 do + S= 12,8). W rzeczywistości przedział ten obejmuje pięcioletni średni roczny zwrot w wysokości 53,3% (8 z 15) środków.

Ryż. 9. Odchylenie standardowe
Należy zauważyć, że w procesie sumowania kwadratów różnic elementy znajdujące się dalej od średniej zyskują większą wagę niż elementy znajdujące się bliżej. Ta właściwość jest głównym powodem, dla którego do oszacowania średniej rozkładu najczęściej używa się średniej arytmetycznej.
Współczynnik zmienności
W przeciwieństwie do poprzednich szacunków rozproszenia, współczynnik zmienności jest szacunkiem względnym. Jest ona zawsze mierzona jako procent, a nie w oryginalnych jednostkach danych. Współczynnik zmienności, oznaczony symbolami CV, mierzy rozproszenie danych wokół średniej. Współczynnik zmienności jest równy odchyleniu standardowemu podzielonemu przez średnią arytmetyczną i pomnożonym przez 100%:

Gdzie S- odchylenie standardowe próbki, - średnia próbki.
Współczynnik zmienności pozwala porównać dwie próbki, których elementy wyrażone są w różnych jednostkach miary. Na przykład menedżer firmy dostarczającej pocztę zamierza zmodernizować flotę ciężarówek. Podczas ładowania paczek należy wziąć pod uwagę dwa rodzaje ograniczeń: wagę (w funtach) i objętość (w stopach sześciennych) każdej paczki. Załóżmy, że w próbce 200 worków średnia waga wynosi 26,0 funtów, odchylenie standardowe masy wynosi 3,9 funta, średnia objętość paczki wynosi 8,8 stopy sześciennej, a odchylenie standardowe objętości wynosi 2,2 stopy sześciennej. Jak porównać rozkład masy i objętości paczek?
Ponieważ jednostki miary masy i objętości różnią się od siebie, menedżer musi porównać względny rozrzut tych wartości. Współczynnik zmienności masy wynosi CV W = 3,9 / 26,0 * 100% = 15%, a współczynnik zmienności objętości CV V = 2,2 / 8,8 * 100% = 25%. Zatem względny rozrzut objętości pakietów jest znacznie większy niż względny rozrzut ich wag.
Formularz dystrybucji
Trzecią ważną właściwością próbki jest forma jej rozkładu. Rozkład ten może być symetryczny lub asymetryczny. Aby opisać kształt rozkładu, należy obliczyć jego średnią i medianę. Jeśli te dwie miary są takie same, mówimy, że zmienna ma rozkład symetryczny. Jeżeli średnia wartość zmiennej jest większa od mediany, jej rozkład ma dodatnią skośność (ryc. 10). Jeżeli mediana jest większa od średniej, rozkład zmiennej jest ujemnie skośny. Dodatnia skośność występuje, gdy średnia wzrasta do niezwykle wysokich wartości. Ujemna skośność występuje, gdy średnia spada do niezwykle małych wartości. Zmienna ma rozkład symetryczny, jeśli nie przyjmuje żadnych ekstremalnych wartości w żadnym kierunku, tak że duże i małe wartości zmiennej znoszą się wzajemnie.

Ryż. 10. Trzy typy dystrybucji
Dane przedstawione na skali A mają ujemną skośność. Ten rysunek przedstawia długi ogon i przechylenie w lewo spowodowane niezwykle małymi wartościami. Te niezwykle małe wartości przesuwają wartość średnią w lewo i staje się ona mniejsza niż mediana. Dane pokazane na skali B rozkładają się symetrycznie. Lewa i prawa połowa rozkładu są ich lustrzanymi odbiciami. Duże i małe wartości równoważą się, a średnia i mediana są równe. Dane pokazane na skali B mają dodatnią skośność. Rysunek ten przedstawia długi ogon i przechylenie w prawo, spowodowane obecnością niezwykle wysokich wartości. Te zbyt duże wartości przesuwają średnią w prawo i staje się ona większa od mediany.
W programie Excel statystyki opisowe można uzyskać za pomocą dodatku Pakiet analityczny. Przejdź przez menu Dane → Analiza danych, w oknie, które zostanie otwarte, wybierz linię Opisowe statystyki i kliknij OK. W oknie Opisowe statystyki koniecznie wskaż interwał wejściowy(ryc. 11). Jeśli chcesz zobaczyć statystyki opisowe w tym samym arkuszu, co dane oryginalne, zaznacz przycisk radiowy interwał wyjściowy i określ komórkę, w której chcesz umieścić lewy górny róg wyświetlanych statystyk (w naszym przykładzie $C$1). Jeśli chcesz wyprowadzić dane do nowego arkusza lub nowego skoroszytu, po prostu wybierz odpowiedni przycisk opcji. Zaznacz pole obok Końcowe statystyki. Opcjonalnie możesz także wybrać Poziom trudności,k-ta najmniejsza ik-ty największy.
Jeśli w depozycie Dane w pobliżu Analiza nie widzisz ikony Analiza danych, musisz najpierw zainstalować dodatek Pakiet analityczny(patrz na przykład).

Ryż. 11. Statystyki opisowe pięcioletnich średniorocznych zwrotów funduszy o bardzo wysokim poziomie ryzyka, obliczonych przy użyciu narzutu Analiza danych Programy Excela
Excel oblicza szereg statystyk omówionych powyżej: średnią, medianę, modę, odchylenie standardowe, wariancję, zakres ( interwał), minimalna, maksymalna i wielkość próbki ( sprawdzać). Dodatkowo Excel wylicza dla nas kilka nowych statystyk: błąd standardowy, kurtozę i skośność. Standardowy błąd równa się odchyleniu standardowemu podzielonemu przez pierwiastek kwadratowy z wielkości próby. asymetria charakteryzuje odchylenie od symetrii rozkładu i jest funkcją zależną od sześcianu różnic pomiędzy elementami próbki a wartością średnią. Kurtoza jest miarą względnej koncentracji danych wokół średniej względem ogonów rozkładu i zależy od różnic między próbą a średnią podniesioną do czwartej potęgi.
Obliczanie statystyk opisowych dla populacji ogólnej
Średnia, rozrzut i kształt rozkładu omówione powyżej są charakterystykami opartymi na próbie. Jeśli jednak zbiór danych zawiera pomiary numeryczne całej populacji, wówczas można obliczyć jej parametry. Parametry te obejmują średnią, wariancję i odchylenie standardowe populacji.
Wartość oczekiwana jest równa sumie wszystkich wartości populacji ogólnej podzielonej przez wielkość populacji ogólnej:

Gdzie µ - wartość oczekiwana, XI- I-ta obserwacja zmienna X, N- wielkość populacji ogólnej. W programie Excel do obliczenia oczekiwań matematycznych używana jest ta sama funkcja, co do średniej arytmetycznej: =ŚREDNIA().
Wariancja populacji równa sumie kwadratów różnic pomiędzy elementami populacji ogólnej i mat. oczekiwanie podzielone przez wielkość populacji:

Gdzie σ2 jest wariancją populacji ogólnej. W programie Excel w wersji wcześniejszej niż 2007 używana jest funkcja =VAR() do obliczania wariancji populacji, począwszy od wersji 2010 =VAR.G().
odchylenie standardowe populacji jest równy pierwiastkowi kwadratowemu wariancji populacji:

W programie Excel w wersji wcześniejszej niż 2007 używana jest metoda =STDEV() do obliczania odchylenia standardowego populacji, począwszy od wersji 2010 =STDEV.Y(). Należy zauważyć, że wzory na wariancję populacji i odchylenie standardowe różnią się od wzorów na wariancję próbki i odchylenie standardowe. Przy obliczaniu przykładowych statystyk S2 I S mianownik ułamka to n - 1 i przy obliczaniu parametrów σ2 I σ - wielkość populacji ogólnej N.
praktyczna zasada
W większości sytuacji duża część obserwacji koncentruje się wokół mediany, tworząc klaster. W zbiorach danych o dodatniej skośności skupienie to znajduje się po lewej stronie (tj. poniżej) oczekiwań matematycznych, a w zbiorach o ujemnej skośności skupienie to znajduje się po prawej stronie (tj. powyżej) oczekiwań matematycznych. Dane symetryczne mają tę samą średnią i medianę, a obserwacje skupiają się wokół średniej, tworząc rozkład w kształcie dzwonu. Jeśli rozkład nie ma wyraźnej skośności, a dane są skupione wokół pewnego środka ciężkości, do oszacowania zmienności można zastosować praktyczną regułę, która mówi: jeśli dane mają rozkład dzwonowy, to około 68% obserwacji jest mniejsza niż jedno odchylenie standardowe od oczekiwań matematycznych, około 95% obserwacji mieści się w granicach dwóch odchyleń standardowych od wartości oczekiwanej, a 99,7% obserwacji mieści się w granicach trzech odchyleń standardowych od wartości oczekiwanej.
Zatem odchylenie standardowe, które jest oszacowaniem średniego wahania wokół oczekiwań matematycznych, pomaga zrozumieć rozkład obserwacji i zidentyfikować wartości odstające. Z praktycznej reguły wynika, że w przypadku rozkładów dzwonowych tylko jedna wartość na dwadzieścia różni się od oczekiwań matematycznych o więcej niż dwa odchylenia standardowe. Dlatego wartości spoza przedziału µ ± 2σ, można uznać za wartości odstające. Ponadto tylko trzy z 1000 obserwacji różnią się od oczekiwań matematycznych o więcej niż trzy odchylenia standardowe. Zatem wartości poza przedziałem µ ± 3σ są prawie zawsze wartościami odstającymi. W przypadku rozkładów, które są mocno skośne lub nie mają kształtu dzwonu, można zastosować praktyczną regułę Biename-Czebyszewa.
Ponad sto lat temu matematycy Bienamay i Czebyszew niezależnie odkryli użyteczną właściwość odchylenia standardowego. Ustalili, że dla dowolnego zbioru danych, niezależnie od kształtu rozkładu, odsetek obserwacji leżących w odległości nie przekraczającej k odchylenia standardowe od oczekiwań matematycznych, nie mniej (1 – 1/ 2)*100%.
Na przykład, jeśli k= 2, reguła Biename-Czebyszewa stwierdza, że co najmniej (1 - (1/2) 2) x 100% = 75% obserwacji musi mieścić się w przedziale µ ± 2σ. Ta zasada dotyczy każdego k przekraczający jeden. Reguła Biename-Czebyszewa ma charakter bardzo ogólny i obowiązuje dla dowolnego rodzaju rozkładów. Wskazuje minimalną liczbę obserwacji, z której odległość do oczekiwań matematycznych nie przekracza zadanej wartości. Jeśli jednak rozkład ma kształt dzwonu, praktyczna zasada pozwala dokładniej oszacować koncentrację danych wokół średniej.
Obliczanie statystyk opisowych dla rozkładu opartego na częstotliwości
Jeżeli oryginalne dane nie są dostępne, jedynym źródłem informacji staje się rozkład częstotliwości. W takich sytuacjach można obliczyć przybliżone wartości ilościowych wskaźników rozkładu, takich jak średnia arytmetyczna, odchylenie standardowe, kwartyle.
Jeśli przykładowe dane zostaną przedstawione w postaci rozkładu częstotliwości, można obliczyć przybliżoną wartość średniej arytmetycznej, zakładając, że wszystkie wartości w obrębie każdej klasy skupiają się w środku klasy:

Gdzie - średnia próbki, N- liczba obserwacji lub wielkość próby, Z- ilość klas w rozkładzie częstotliwości, mj- punkt środkowy J- klasa, FJ- częstotliwość odpowiadająca J- klasa.
Aby obliczyć odchylenie standardowe z rozkładu częstotliwości, zakłada się również, że wszystkie wartości w obrębie każdej klasy skupiają się w środku klasy.

Aby zrozumieć, w jaki sposób wyznaczane są kwartyle szeregu na podstawie częstości, rozważmy obliczenie dolnego kwartyla na podstawie danych za 2013 rok dotyczących rozkładu ludności Rosji według średniego dochodu pieniężnego na mieszkańca (ryc. 12).

Ryż. 12. Udział ludności Rosji w średnim miesięcznym dochodzie pieniężnym na mieszkańca, ruble
Aby obliczyć pierwszy kwartyl szeregu zmian przedziału, możesz skorzystać ze wzoru:

gdzie Q1 jest wartością pierwszego kwartyla, xQ1 jest dolną granicą przedziału zawierającego pierwszy kwartyl (przedział wyznacza się na podstawie skumulowanej częstotliwości, z której pierwszy przekracza 25%); i jest wartością przedziału; Σf jest sumą częstotliwości całej próbki; prawdopodobnie zawsze równa 100%; SQ1–1 to skumulowana częstotliwość przedziału poprzedzającego przedział zawierający dolny kwartyl; fQ1 to częstotliwość przedziału zawierającego dolny kwartyl. Wzór na trzeci kwartyl różni się tym, że we wszystkich miejscach zamiast Q1 należy zastosować Q3 i zastąpić ¾ zamiast ¼.
W naszym przykładzie (ryc. 12) dolny kwartyl mieści się w przedziale 7000,1–10 000, którego skumulowana częstotliwość wynosi 26,4%. Dolna granica tego przedziału wynosi 7000 rubli, wartość przedziału wynosi 3000 rubli, skumulowana częstotliwość przedziału poprzedzającego przedział zawierający dolny kwartyl wynosi 13,4%, częstotliwość przedziału zawierającego dolny kwartyl wynosi 13,0%. Zatem: Q1 \u003d 7000 + 3000 * (¼ * 100 - 13,4) / 13 \u003d 9677 rubli.
Pułapki związane ze statystyką opisową
W tej notatce przyjrzeliśmy się, jak opisać zbiór danych za pomocą różnych statystyk, które szacują jego średnią, rozrzut i rozkład. Następnym krokiem jest analiza i interpretacja danych. Do tej pory badaliśmy obiektywne właściwości danych, a teraz przechodzimy do ich subiektywnej interpretacji. Na badacza czyhają dwa błędy: źle wybrany przedmiot analizy i błędna interpretacja wyników.
Analiza wyników 15 funduszy inwestycyjnych bardzo wysokiego ryzyka jest dość bezstronna. Doprowadził do całkowicie obiektywnych wniosków: wszystkie fundusze inwestycyjne mają różną stopę zwrotu, spread zwrotów funduszy waha się od -6,1 do 18,5, a średnia stopa zwrotu wynosi 6,08. Obiektywizm analizy danych zapewnia właściwy dobór całkowitych wskaźników ilościowych rozkładu. Rozważono kilka metod szacowania średniej i rozrzutu danych oraz wskazano ich zalety i wady. Jak wybrać odpowiednie statystyki, które zapewnią obiektywną i bezstronną analizę? Jeżeli rozkład danych jest lekko przekrzywiony, czy należy wybrać medianę, a nie średnią arytmetyczną? Który wskaźnik dokładniej charakteryzuje rozrzut danych: odchylenie standardowe czy zakres? Czy należy wskazać dodatnią skośność rozkładu?
Z drugiej strony interpretacja danych jest procesem subiektywnym. Różni ludzie dochodzą do różnych wniosków, interpretując te same wyniki. Każdy ma swój własny punkt widzenia. Ktoś uważa łączną średnioroczną stopę zwrotu 15 funduszy o bardzo wysokim poziomie ryzyka za dobrą i jest całkiem zadowolony z uzyskiwanych dochodów. Inni mogą pomyśleć, że fundusze te mają zbyt niską stopę zwrotu. Subiektywność powinna więc być rekompensowana uczciwością, neutralnością i jasnością wniosków.
Zagadnienia etyczne
Analiza danych jest nierozerwalnie związana z kwestiami etycznymi. Należy krytycznie odnosić się do informacji rozpowszechnianych przez prasę, radio, telewizję i Internet. Z biegiem czasu nauczysz się być sceptyczny nie tylko wobec wyników, ale także celów, przedmiotu i obiektywności badań. Najlepiej ujął to słynny brytyjski polityk Benjamin Disraeli: „Są trzy rodzaje kłamstw: kłamstwa, przeklęte kłamstwa i statystyki”.
Jak zauważono w nocie, przy wyborze wyników, które powinny zostać zaprezentowane w raporcie, pojawiają się kwestie etyczne. Należy opublikować zarówno wyniki pozytywne, jak i negatywne. Ponadto sporządzając raport lub raport pisemny, wyniki muszą być przedstawione rzetelnie, neutralnie i obiektywnie. Rozróżnij prezentację złą i nieuczciwą. Aby to zrobić, konieczne jest ustalenie, jakie były intencje mówiącego. Czasami mówiący pomija ważne informacje z niewiedzy, a czasem celowo (np. jeśli posługuje się średnią arytmetyczną do oszacowania średniej wyraźnie wypaczonych danych, aby uzyskać pożądany rezultat). Nieuczciwe jest także ukrywanie wyników, które nie odpowiadają punktowi widzenia badacza.
Wykorzystano materiały z książki Levin i wsp. Statystyki dla menedżerów. - M.: Williams, 2004. - s. 178–209
Funkcja KWARTYL zachowana w celu dostosowania do wcześniejszych wersji programu Excel